Nextjs 검색엔진 최적화

SEO 최적화를 위해 해야할 것들
블로그이기 때문에 검색엔진 최적화를 해보기에 적합하다고 생각했고, Nextjs를 선택한 이유기도 하기 때문에 검색엔진 최적화를 결정했다.
블로그 주소 최적화
위 문서에 따르면 구글에서는 posts/2131vbjbdsf같은 랜덤 형식의 주소보다 의미를 알아볼 수 있는 주소를 권장한다고 한다.
// example
// 좋은 예
const url = 'https://blog.com/how-to-work';
// 나쁜 예
const url = 'https://blog.com/3';
지금 내가 만든 블로그에서는 정확하게 아래의 나쁜 예와 일치한다.. 그래서 이걸 어떻게 바꿔야할까 생각해봤을 때, 떠오른 방법은 글의 제목을 기준으로 id를 만드는 것이다.
티스토리 블로그의 경우 처음 글을 발행할때의 기준으로 글의 slug를 만든다.
Slug와 Id는 같은 개념인가?
아니라고 한다. 둘 다 같은 개념으로 사용할 수는 있지만 일반적으로, id는 따로 존재하고 slug는 검색엔진, 데이터 조회를 위한 방법으로 사용된다.
그래서 slug를 검색엔진 최적화를 위해서 id와 독립적으로 사용하기로 결정했다.
Slug 생성하기
slug는 글의 제목을 기준으로 생성하도록 구현했다. 띄어쓰기는 -를 사용해서 연결하고 특수문자들은 제거하는 방식으로 slug를 생성하도록했다.
만약 같은 제목의 글이라면?
물론 같은 제목의 글을 작성할 일은 많지 않겠지만 slug는 글을 조회할 때도 사용해야하기 때문에, unique 해야한다. 그래서 같은 slug일 경우 slug 뒤에 번호를 붙여주는 방식으로 중복을 방지했다.
테스트코드
유틸 함수는 테스트 코드를 통해 검증하는 방식을 사용했다. 특수문자나, 물음표 제거 등의 동작을 테스트하고, 중복 슬러그 생성도 검증하도록 테스트코드를 작성했다.
test('중복된 slug 생성', async () => {
const title = '중복된 제목';
const Post = {
findOne: jest
.fn()
.mockReturnValueOnce({ slug: '중복된-제목' })
.mockReturnValueOnce(null),
};
const slug = await generateUniqueSlug(
title,
Post as unknown as Model<Post>
);
expect(slug).toBe('중복된-제목-1');
});
결과
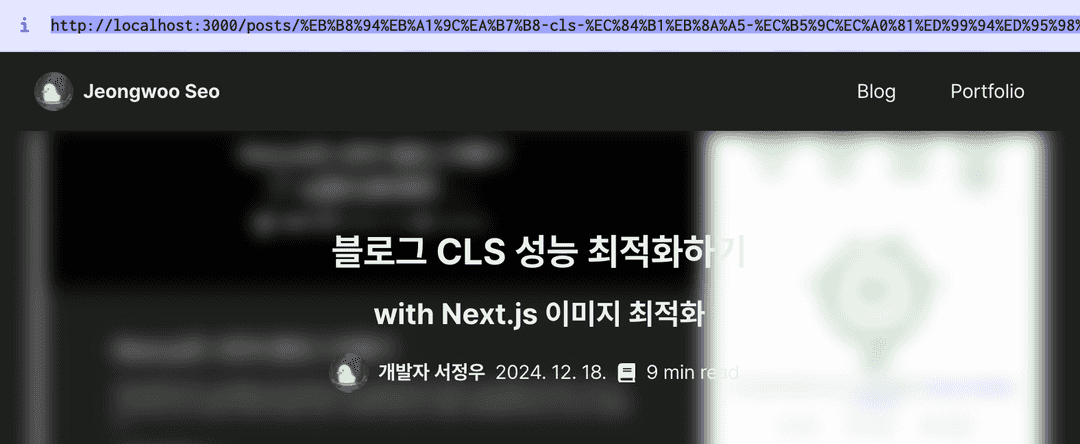
이제 http://localhost:3000/posts/블로그-cls-성능-최적화하기 같은 주소로 접근하면 글을 조회할 수 있도록했다.
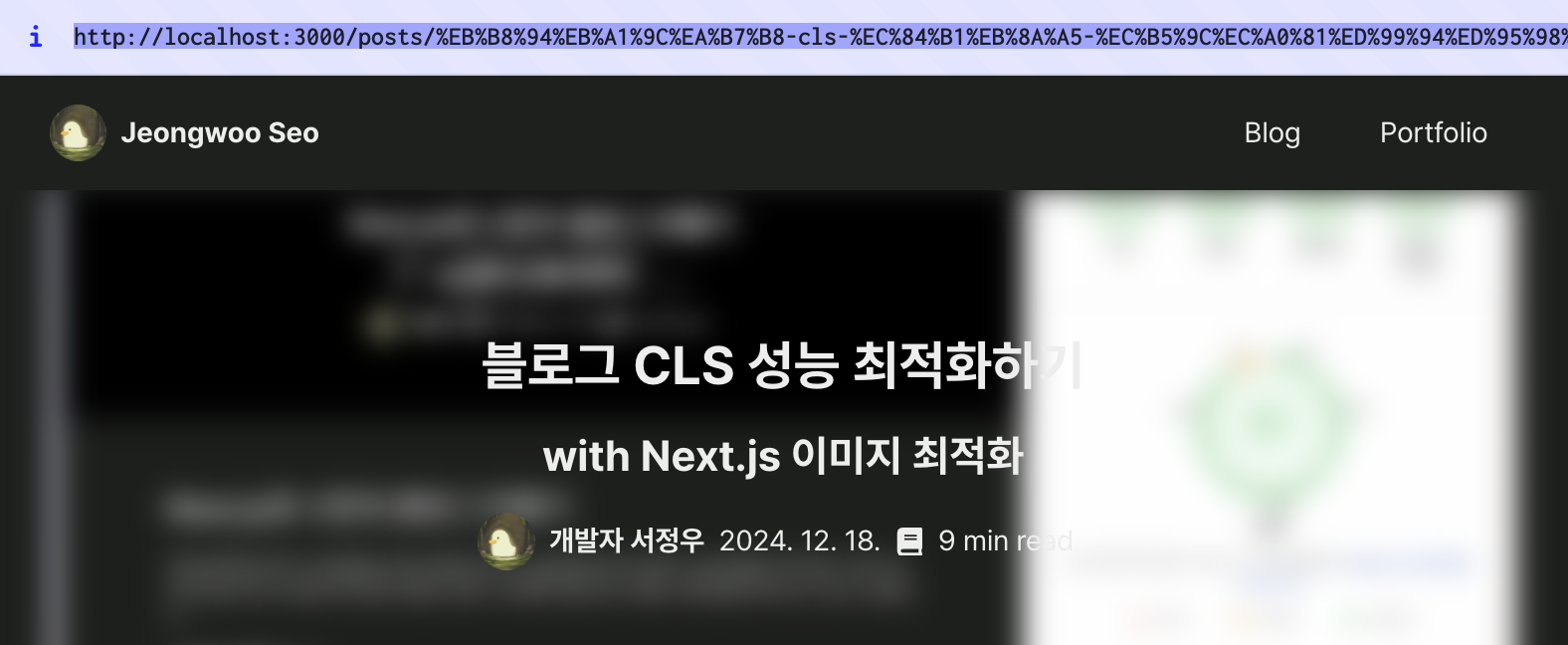 image.png
image.png
NextJS 메타데이터와 Server Action
NextJS는 서버 컴포넌트를 지원하기 때문에 SEO에 유리하다. 이걸 개념적으로만 알고 있었는데 이번에 SEO 최적화를 진행하면서 왜 SEO에 좋은지 알게 되었다. 서버 컴포넌트로 만들어서 서버에서 페이지의 metadata를 미리 만들어서 유저에게 전달하는 방식을 사용하고 있다.
NextJS Metadata 생성
전통적인 서버사이드렌더링을 하는 서비스에서는 메타데이터가 서버에서 만들어져있기 때문에 검색엔진 색인에 유리하다. 하지만 SPA는 자바스크립트를 통해 페이지를 생성하기 때문에 동적인 metadata 생성에 취약할 수 밖에 없다.
NextJS에서는 metadata를 아래와 같이 동적으로 생성해 내보내기 하면 자동으로 페이지의 메타데이터를 만들어준다.
export const generateMetadata = async ({
params,
}: {
params: { slug: string };
}): Promise<Metadata> => {
const { post } = await getPostDetail(params.slug);
return {
title: post.title,
description: post.subTitle || post.content.substring(0, 160),
openGraph: {
title: post.title,
description: post.subTitle || post.content.substring(0, 160),
images: [(post.thumbnailImage as string) || (example2.src as string)],
},
};
};
하지만 주의할 점은 이런 Metadata를 만들어 내보내기 하는 것은 서버 컴포넌트만 지원한다. 서버 컴포넌트의 경우 Next가 서버에서 미리 만들어서 보내주는데, 이 과정에서 메타데이터를 지정해주는 것이다.
그래서 기존의 글 세부 페이지를 서버 컴포넌트로 만들 필요가 있었다. 처음에는 API를 분리해서 상태없이 렌더링을 하도록 했다. 그러나 서버 컴포넌트의 경우에는 API로 연결할 필요 없이 서버 액션을 사용해서 바로 DB에서 값을 조회하는게 더 이득이라는 것을 알게 되었다.
Server Action 동작 안됨 이슈
기존의 API를 사용하던 부분을 NextJS 서버 액션을 사용해서 직접 DB를 조회하는 방식을 사용했다. 풀스택 프레임워크다보니 이런게 좋은 것 같다.
그런데 직접 DB를 조작하려니까 slug로 글 데이터를 찾을 수 없는 문제가 생겼다.
문제가 생긴 서버 액션 코드, 이 코드는 프론트엔드 app/posts/[slug]/page.tsx 파일 내부에 작성된다. 프론트엔드에서 API 요청과 응답을 처리하는 단계를 건너뛰고 직접 DB를 찌르는 방식이다. 그렇다보니 서버 사이드 렌더링에 적합한 방법인 것 같다.
async function getPostDetail(slug: string) {
await dbConnect();
const post = await Post.findOne({ slug: slug }).lean();
if (!post) {
throw new Error('Post not found');
}
return { post: JSON.parse(JSON.stringify(post)) };
}
그러나… Post Not Found 문제가 발생했다.
어라? 분명 API를 사용했을 때는 정상적으로 작동했는데, slug로 포스트가 검색되지 않는 문제였다. 처음에는 DB와의 연결문제인줄 알고 확인했으나 DB는 정상적으로 연결되고 있었다.
// 서버 로그
slug %EB%B8%94%EB%A1%9C%EA%B7%B8-cls-%EC%84%B1%EB%8A%A5-%EC%B5%9C%EC%A0%81%ED%99%94%ED%95%98%EA%B8%B0
post null
⨯ app/posts/[slug]/page.tsx (19:11) @ $$ACTION_0
⨯ Error: Post not found
at $$ACTION_0 (./app/posts/[slug]/page.tsx:36:15)
at async Module.generateMetadata (./app/posts/[slug]/page.tsx:43:22)
digest: "1908036914"
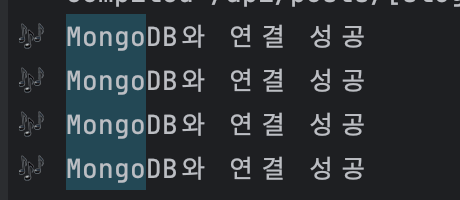 image.png
image.png
use server를 붙여야하나?
‘use client’ 같은 지시어를 붙여야하나 해서 ‘use server’를 사용해봤다. 하지만 결과는 같았다.
이 과정에서 use server의 역할을 알게 되었다. use server는 이 함수가 서버에서만 실행된다고 명시해주는 역할이라고 한다.
async function getPostDetail(slug: string) {
'use server';
await dbConnect();
const post = await Post.findOne({ slug: slug }).lean();
if (!post) {
throw new Error('Post not found');
}
return { post: JSON.parse(JSON.stringify(post)) };
}
decodeURIComponent
같은 코드인데 서버 API에서는 실행되고 서버 액션에서는 실행되지 않는다는 점에서, slug의 인코딩 문제임을 깨닫게 되었다. 서버에 요청을 보낼 때에는 한글로 되어있는 slug를 보내고 제대로 실행되지만, 브라우저에서는 보통 한글 주소를 encoding하기 때문에 %d2 이런식으로 인코딩되어있다. 이걸 사용해서 db에서 검색하니 검색되지 않는 것이 문제였다.
이를 해결하기 위해서, decodeURIComponent를 사용했다. 이 함수는 인코딩된 문자열을 원래대로 복구해주는 함수이다. 반대의 기능으로는 encodeURIComponent가 있다. 이걸 아래와 같이 수정해주니 정상적으로 작동했다.
const post = await *Post*.findOne({ slug: decodeURI(slug) }).lean();
위와 같은 여정을 거쳐 아래처럼 meta 태그가 동적으로 생성되는 것을 확인할 수 있다. 이제 이 데이터를 기반으로 구글은 내 글들을 수집해갈 것이다.
 image.png
image.png
Sitemap과 Robot.txt
이 둘은 검색엔진 최적화에서 자주 언급되는 개념이다. 사이트맵은 서비스에 어떤 페이지들이 있는지 링크와 설명 등을 적는 파일이다. 이걸로 검색엔진 봇들이 사이트를 크롤링한다고 생각하면 된다.
robot.txt는 검색엔진에게 어떤 페이지를 허용할지 비허용할지 등을 정할 수 있고, 특정 검색엔진에서의 크롤링을 제한하는 등의 기능을 지원한다.
Next.js에서의 sitemap, robot
이번에 next로 프로젝트를 하면서 재미있는 점이 이런 점인 것 같다. nextjs에서는 app 폴더 내부에 sitemap.ts, robot.ts 같이 타입스크립트로 작성하면 알아서 sitemap.xml, robot.txt 파일로 생성해준다고 한다.
Sitemap.ts
사이트맵은 아래와 같이 작성할 수 있다. dbConnect를 사용해서 앞으로 생성될 포스트들에 대해서도 사이트맵을 생성해주는 역할을 수행한다.
import { MetadataRoute } from 'next';
import dbConnect from '@/app/lib/dbConnect';
import Post from '@/app/models/Post';
export default async function sitemap(): Promise<MetadataRoute.Sitemap> {
await dbConnect();
const posts = await Post.find({}).sort({ date: -1 });
const baseUrl = process.env.NEXTAUTH_URL || 'http://localhost:3000';
// 정적 페이지 URL
const staticPages = [
{
url: baseUrl,
lastModified: new Date(),
changeFrequency: 'daily' as const,
priority: 1,
},
{
url: `${baseUrl}/posts`,
lastModified: new Date(),
changeFrequency: 'weekly' as const,
priority: 0.8,
},
];
const postUrls = posts.map((post) => ({
url: `${baseUrl}/posts/${post.slug}`,
lastModified: new Date(post.updatedAt || post.date),
changeFrequency: 'weekly' as const,
priority: 0.7,
}));
return [...staticPages, ...postUrls];
}
JSONLd 컴포넌트
이건 전에 들어본 적이 없는 개념이었다. JSONLd를 사용하면 페이지에 대한 세부 설명을 작성할 수 있다고 이해했다. 구글이나 네이버 검색을 하다보면 snippet 형태로 보여주는 부분이 있는데 이게 jsonld를 사용하면 가능하다고 한다.
JSON-LD
JavaScript Object Notation for LInked Data의 약자이다. JSON 형식을 사용해서 링크드 데이터를 표현하는 데이터 직렬화 방식이다.
여기에 들어가는 데이터는 아래처럼 다양하게 존재한다. 주소, 전화번호 같은 데이터부터, 언제 마지막으로 수정되었는지, 무슨 목적의 페이지인지 등을 기재할 수 있도록 되어있다.
{
"@context": "https://schema.org",
"@type": "Restaurant",
"name": "맛있는 집",
"address": {
"@type": "PostalAddress",
"streetAddress": "서울특별시 강남구 테헤란로 123",
"addressLocality": "서울",
"postalCode": "12345",
"addressCountry": "KR"
},
"telephone": "+82-2-1234-5678",
"servesCuisine": "Korean",
"openingHours": "Mo-Sa 11:00-22:00"
}
이 JSON-LD는 HTML <script> 태그에 삽입하거나 별도로 관리할 수 있어 다양한 환경에서 활용 가능하다. 이번 프로젝트에서는 각 블로그 페이지마다 이 json-ld를 지정해주는 컴포넌트를 만들고자 했다.
script 태그를 사용해서 ld+json 형식으로 제목,소제목, 본문, 저자와 글자 수, 그리고 읽는데 소요되는 시간 등을 지정해주었다.
import { Post } from '@/app/types/Post';
const PostJSONLd = ({ post }: { post: Post }) => {
return (
<script
type="application/ld+json"
dangerouslySetInnerHTML={{
__html: JSON.stringify({
'@context': 'https://schema.org',
'@type': 'BlogPosting',
headline: post.title,
alternativeHeadline: post.subTitle, // 서브타이틀용
description: post.subTitle || post.content.substring(0, 160),
articleBody: post.content, // 본문 전체
author: {
'@type': 'Person',
name: post.author,
},
datePublished: new Date(post.date).toISOString(),
dateModified: new Date(post.updatedAt || post.date).toISOString(),
wordCount: post.content.split(/\s+/g).length,
timeRequired: `PT${post.timeToRead}M`, // ISO 8601 duration format
// 이미지가 있는 경우
image: post.thumbnailImage,
// 블로그/사이트 정보
publisher: {
'@type': 'Organization',
name: 'ShipFriend TechBlog',
logo: {
'@type': 'ImageObject',
url: `https://oraciondev.vercel.app/favicon.ico`,
},
},
}),
}}
/>
);
};
export default PostJSONLd;
위 컴포넌트는 블로그 세부 페이지에 아래와 같이 렌더링 해주었다.
return (
<>
<PostJSONLd post={post} />
<section className="bg-transparent w-full flex-grow">
<article className="post">
<PostHeader
title={post?.title || ''}
subTitle={post?.subTitle || ''}
author={post?.author || ''}
date={post?.date || 0}
timeToRead={post?.timeToRead || 0}
backgroundThumbnail={post?.thumbnailImage || example2}
/>
<PostBody loading={false} content={post?.content || ''} />
</article>
<Comments />
</section>
</>
);